寂井浮廊
打赏我
欢迎您:
游客
登录
发现BUG请联系jintianhu2000@126.com
常用
加解密算法
常用工具
EMV相关
还珠楼论坛
答题闯关
用户信息
帖子列表
语法介绍
帖子详情
C代码文件UTF8格式带来的问题
jin.th 发布于2018-11-01 15:51
[评论区]
[我要回复]
[下载md文件]
[下载pdf文件]
仅自己可见
初衷是将原本在IAR、VS上的C代码移植到Android Stdio和Xcode上,但Android Stdio和Xcode上的C代码文件必须是UTF8格式,不然所有中文注释都是乱码。 用记事本将代码文件另存为成UTF8格式后,会在文件最开头加上三个字节EFBBBF,这叫UTF8 BOM,参看[这里](https://blog.csdn.net/legendaryhsl/article/details/78794121 "这里")。但是IAR不认,会编译报错认为那是非法字符。 用VS将代码文件改成UTF-8带签名,文件最开头会有BOM。 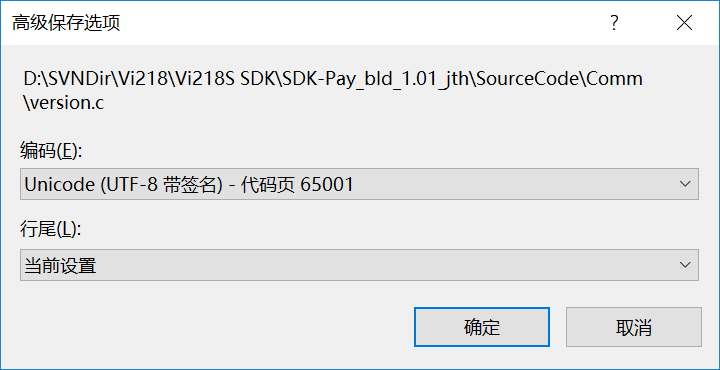 UTF-8无签名就是不带BOM。 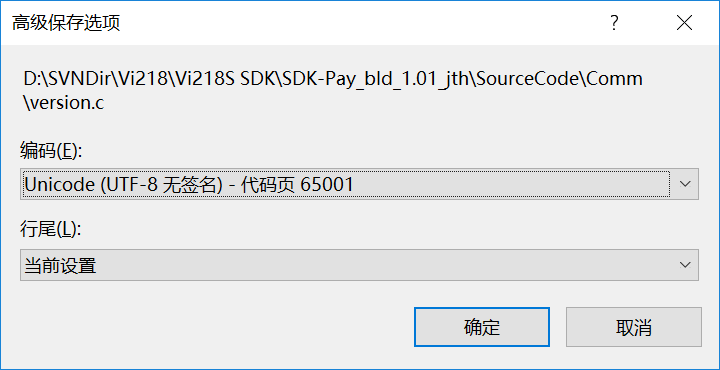 但是问题来了,如果代码中硬编码了中文字符串,不带BOM格式的代码文件在VS中会出现这个错误:**error C2001:常量中有换行符** 网上的解决方案是 (1)全部用英文编码,不要用中文 (2)偶数中文 或 结尾加英文的符号,如"." 带BOM格式的不会出现这个错误,但是IAR不识别BOM会编译报错。而且如果代码中硬编码了中文字符串,所有函数是按GB2312来处理入参的字符串的,如果改成UTF-8会出错。 这就导致一份代码同时在IAR、VS、Android Stdio上同时运行且中文都能显示正常的美好想法破灭,最终我决定,在VS和IAR编译时仍然使用GB2312编码,当需要在xcode和andriod stdio中编译时,用一个小工具将代码文件自动转成UTF-8编码。 **后记** 关于UTF8,还有个有趣的现象。在WINDOWS下用基本新建个文本文件,输入`联通`两字  直接保存后关闭,再打开,就变成乱码了  因为记事本默认是以ANSI编码存储,意思是使用计算机的本地编码,详见[ANSI是什么编码](https://blog.csdn.net/imxiangzi/article/details/77370160)。我们在CMD窗口输入`chcp`即可看到本地编码 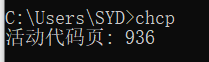 936表示GBK编码,而`联通`两字的GBK编码为`C1AACDA8`,转成二进制就是 ``` C1 = 1100 0001 AA = 1010 1010 CD = 1100 1101 A8 = 1010 1000 ``` 第一二个字节、第三四个字节的起始部分的都是"110"和"10",正好与UTF8规则里的两字节模板是一致的,于是再次打开记事本时,记事本就误认为这是一个UTF8编码的文件。 如果不仅仅输入`联通`这两个字,或者不采用默认的保存方式,就不会发生这样的错误了。
评论列表
回帖
浙ICP备17051204号